

The Janitor Package in R for Cleaning and Examining Data
As a trainer, my role is to show my students better ways of working. If I am successful, they leave my class with the skills to get things done faster, more accurately and with less time spent on boring, repetitive tasks. And as someone who works with data, I am always looking for tools that will make my life easier. Working with the R programming language, there are always new discoveries to be made amongst the nearly 18,000 packages created by the user community.
My latest discovery is the package janitor. It contains easy-to-use and convenient functions for cleaning and examining data. Let's take a look at some of these functions.
1. clean_names()
This function is used to change and clean up names of columns in data frames. It can be used to ensure consistency. You can choose to change all names to snake case (all lower case words, separated by underscores), variations on camel case (internal capital letters between words), title case or other styles. It can also be used to remove parts of names and any special characters, including replacing % symbols with the word percent.
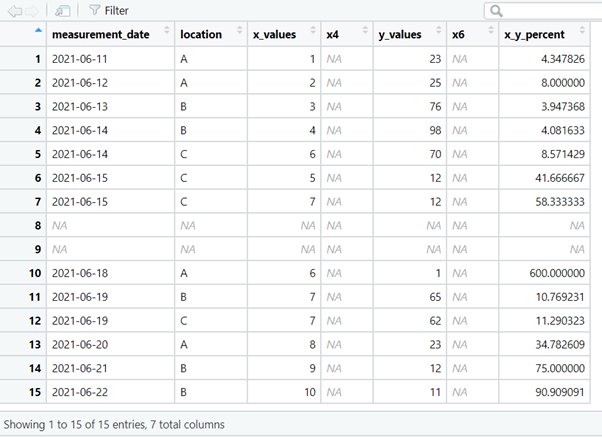
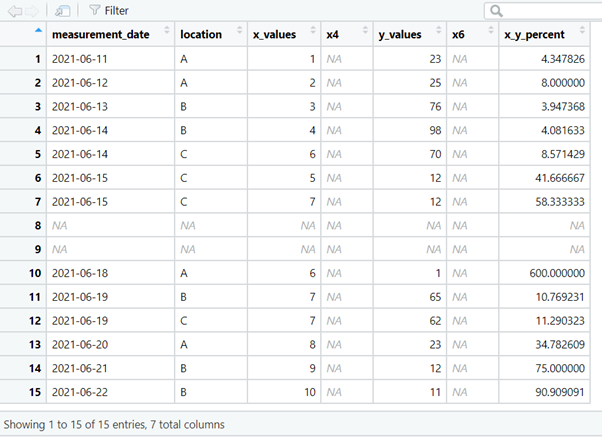
To demonstrate functionality from the janitor package, a dataset was created in Excel.
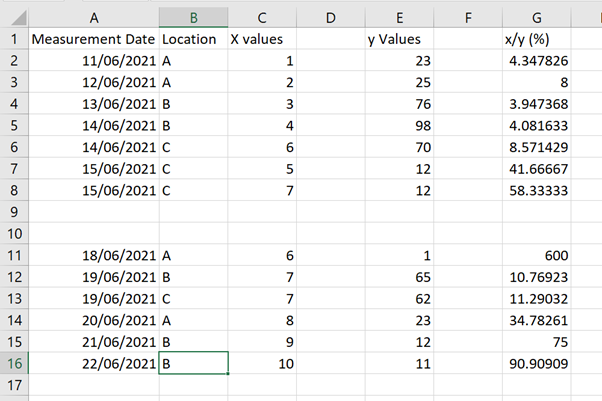
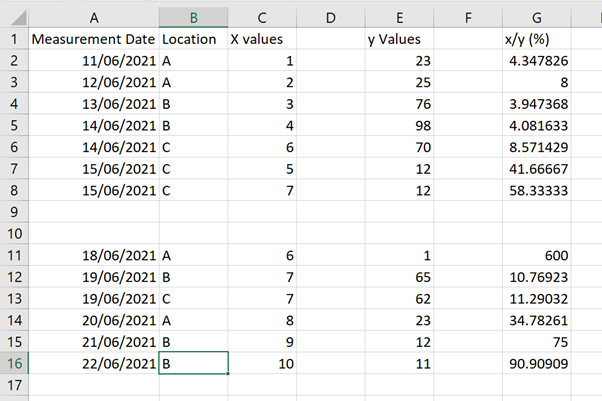
The data were imported into a data frame (df) using the RStudio GUI From Excel… option.


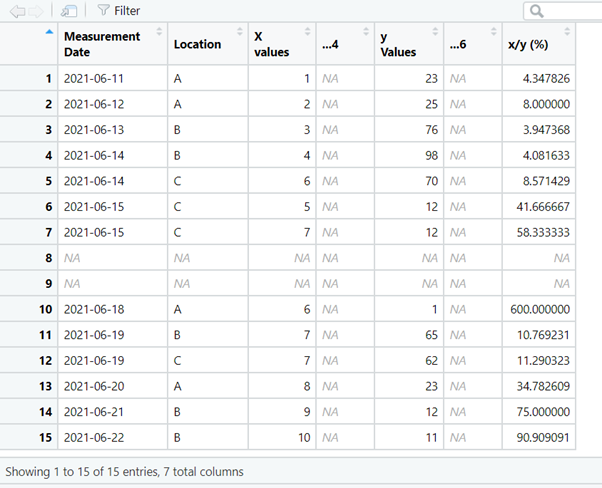
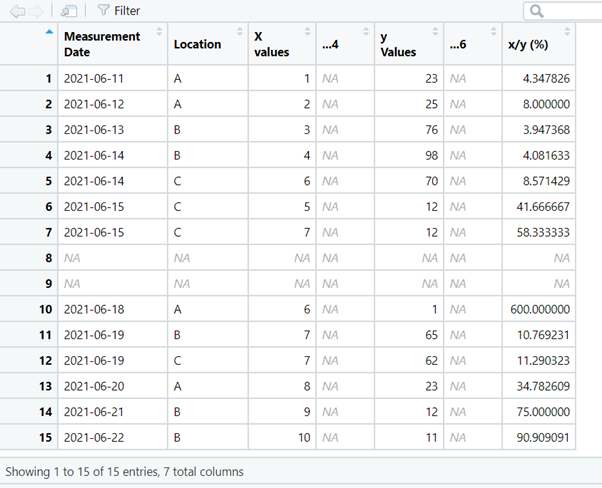
Using the clean_names() function adds consistency to the names, removes spaces in the names and special characters.

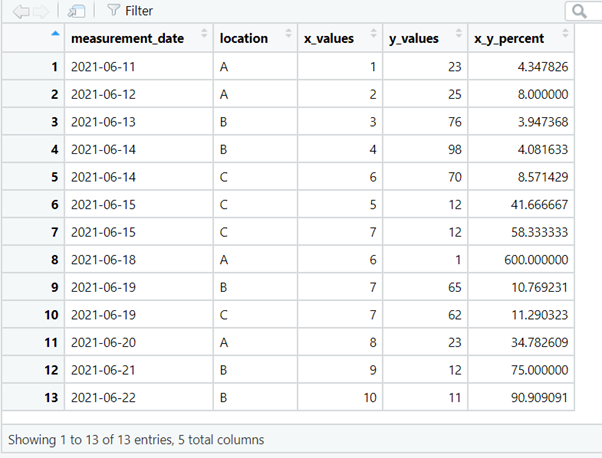
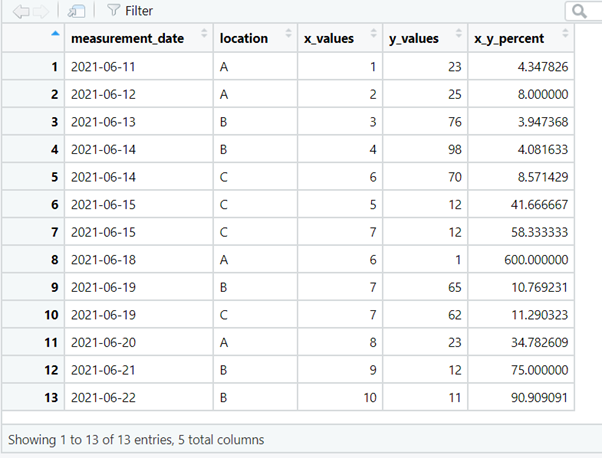
2. remove_empty()
The dataset contains empty rows and empty columns that can be removed with the remove_empty() function.


3. get_dupes()
This function retrieves any duplicates in the dataset so that they can be examined during data clean-up operations. The first argument accepts the name of the data frame, the second and subsequent arguments accept one or more column names. These columns are searched for duplicate values. The function returns a data frame which includes a dupe_count column containing the number of duplicates of that value.
We can search for duplicated measurements on certain dates,


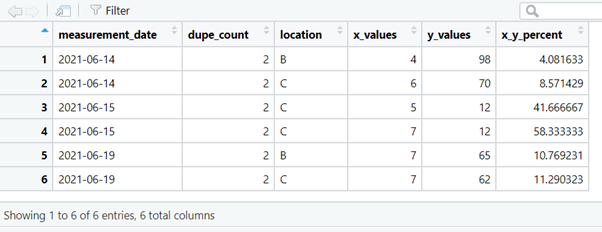
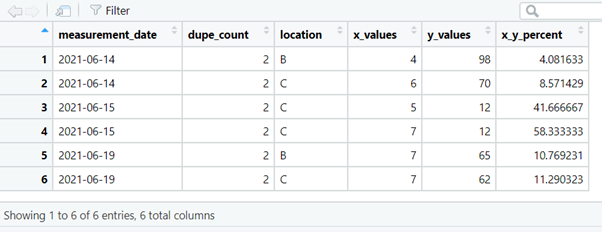
or for duplicated measurements on certain dates, at certain locations.


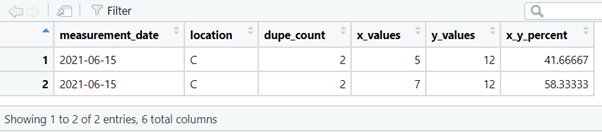
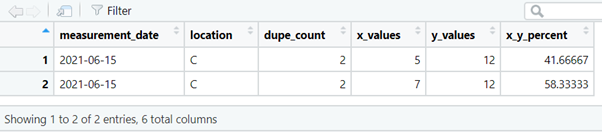
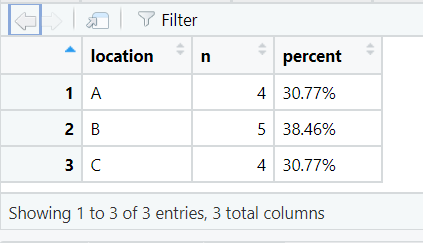
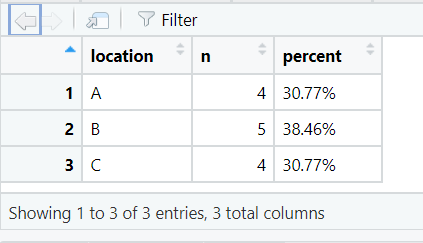
4. tabyl()
This function is used to produce frequency tables and contingency tables, i.e. counts of each category or combination of categories of data. Unlike the base R table() function, tabyl() returns a data frame which makes results easier to work with.
The code below creates a data frame showing the number of rows of data (n) for each location in the dataset. Also returned is a percent column, showing the percentage of rows containing data for that location.


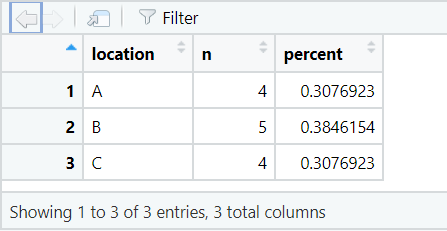
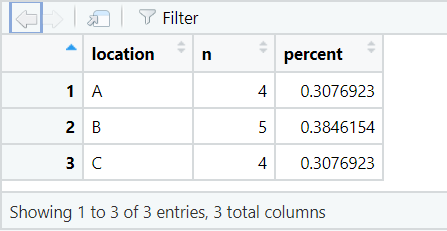
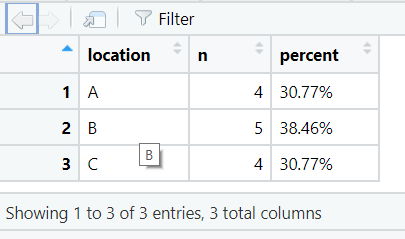
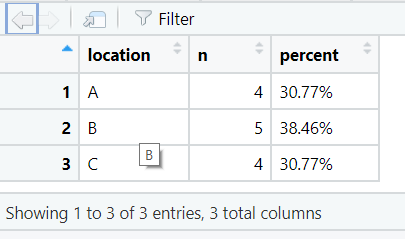
5. adorn_
Janitor also provides adorn_ functions for formatting tabulated data. adorn_pct_formatting() can be used to format the percentage output.

We can also return the number of observations for each location on each date.
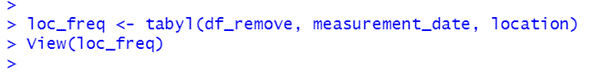
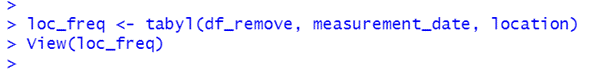
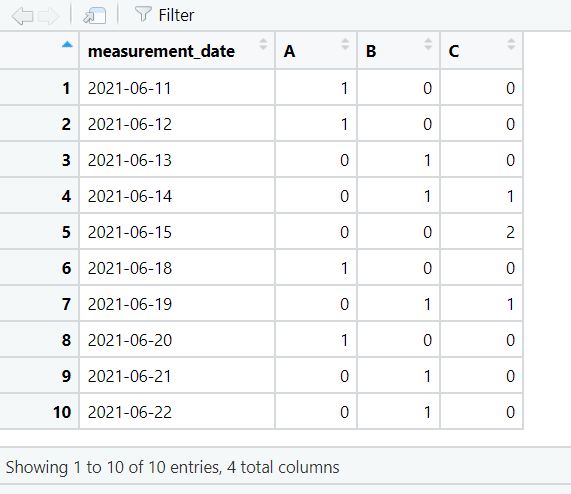
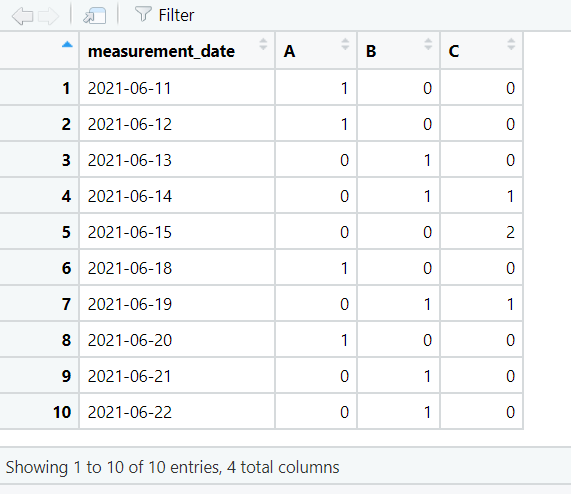
By default the values in the contingency table are shown as counts. They can be changed to percentages using adorn_percentages().


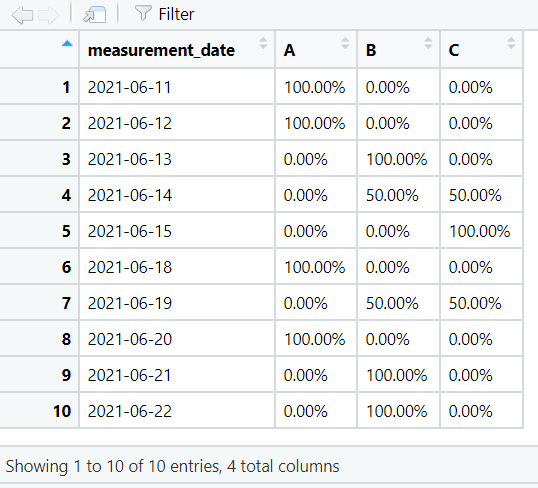
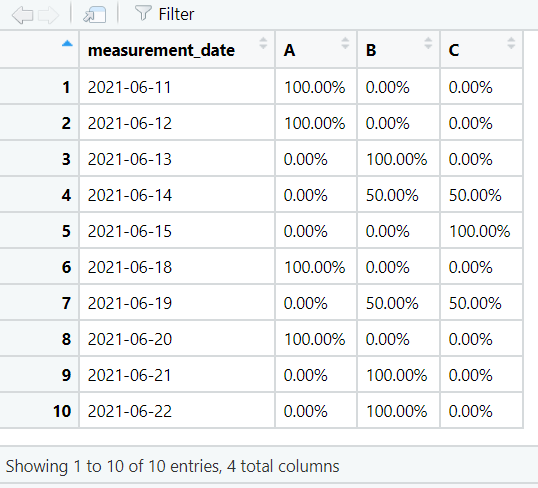
Use janitor functions with tidyverse pipes
If you use tidyverse pipes, you can use janitor functions in your pipelines to streamline data frame clean-up.
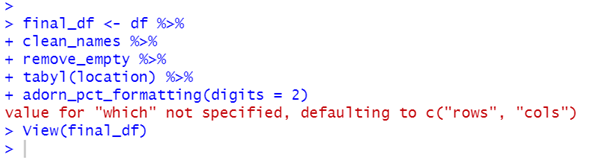
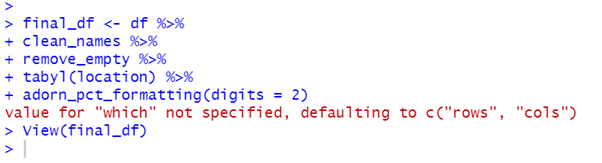
Learn more about janitor at the CRAN site.
If you're new to R, check out our R training course and certifications. We recommend R programming basics for beginners!

























